




















No organization can operate within its industry-specific cybersecurity frameworks without an effective classification schema built into its Identity Governance and Administration (IGA) system. In this post, we’ll define classification in IGA and explain how a risk-based approach to classification provides the best way to meet ongoing compliance challenges. We’ll reveal the principal considerations for creating a classification schema that maps to your unique needs and provide examples of what your approach should look like.
What is classification in Identity Governance and Administration?
Classification in IGA refers to the process of categorizing identities, roles, permissions, and other relevant entities within an organization’s IT infrastructure. This classification is essential for managing access rights, ensuring compliance, enhancing security, and streamlining administrative tasks. No two organizations will use the same classification process. Every entity must begin by asking what the business case is they are addressing and what specific risks they are trying to mitigate.
A classification process must map to an overall corporate strategy within the context of your organization’s IT strategy. Within the IT strategy, the classification process must address specific industry regulations (e.g., NIST, COBIT5, HIPAA, SOX, GDPR, etc.), compliance requirements, and standards frameworks. These are the principal drivers that inform a classification scheme.
A risk-based approach to classification
As you consider the specifics that will drive your process, your fundamental approach must be to differentiate high-risk and low-risk classification. Your high-level roadmap should include the following:
- Inventory all the data and applications in your organization’s IT infrastructure.
- Label each item and assign it to an internal owner.
- Each owner must classify the items for which they are responsible.
- Determine access restriction; who can see the items, how access is provisioned and de-provisioned, who owns the approvals process, who managed access re-certification, etc.
Above all, your risk-based approach must consider the consequences of unauthorized disclosure of specific assets. This can be looked at in these degrees:
- Disclosure would result in no harm.
- Disclosure would result in minor reputational damage.
- Disclosure would result in a significant, short-term adverse impact on the organization.
- Disclosure would result in a credible existential threat to the organization.
Most organizations use existing business tools to classify data and applications internally, but there is a disconnect between how the organization manages data and applications and how an IGA system manages access. For example, an organization may have a SharePoint folder that contains both public and sensitive assets at any given time. An IGA solution cannot determine if or when sensitive assets are added and removed. This is why a context-driven classification scheme is so critical to an effective IGA strategy.
What should an organization classify in the IGA system?
The best place to start when fleshing out the answer is to refer to regulatory and standards documentation that is specific to your industry. This will provide important context that drives your classification process. Do regulations call for the protection of individual privacy? Does your organization need to reduce the risk of exposing sensitive data like financial transactions? Do you need to provide transparency to industry standards and/or demonstrate your organization is enforcing rules?
What do your industry-specific standards require?
In many instances, industry standards require organizations to analyze gaps in their system that stop them from being fully compliant and create a plan to bridge these gaps. Good identity lifecycle management is critical to this effort, enabling you to grant, secure, and control people’s access at the right time. Industry standards usually call for specific documentation and reporting that demonstrates compliance with requirements.
Your classification scheme should map to these requirements, and you must create categories and tags that help meet them. Start with creating a hierarchy to access specific resources based on roles and reserve privileged access tags only for administrators whenever possible. This approach enables you to use categories and tags to fine-tune risk assessments based on individuals’ organizational roles. You should also create categories and tags based on business roles to enforce the strictest access requirements and provide only enough access for users to do their jobs in a specific part of the business.
Six key considerations for effective classification schema design
1. The business purpose: All classification groups should be supplemented with a description of the business purpose. Individual tags within a classification category should also be supported with a concise, easy-to-understand description of why they exist.
2. Hierarchical structure: The schema may organize categories into levels or subcategories. This enables a more granular classification system and helps organize and navigate large amounts of data.
3. Rules for classification of items: Rules and consequences should be objective, consistent, and well-defined. Rules should help ensure that applications and application roles are assigned the correct classification.
4. Documentation considerations: Explain the purpose and scope of the classification schema. Describe the categories and attributes and provide examples. Offer guidance to users on how to apply the classification criteria.
5. Apply quality control: Implement governance to ensure classification consistency and accuracy. Identify and correct classification errors through reviews, audits, and validation processes.
6. Collect user feedback: Enables users to provide input, report issues, and suggest improvements that will refine and improve the schema over time.
Classification schema examples
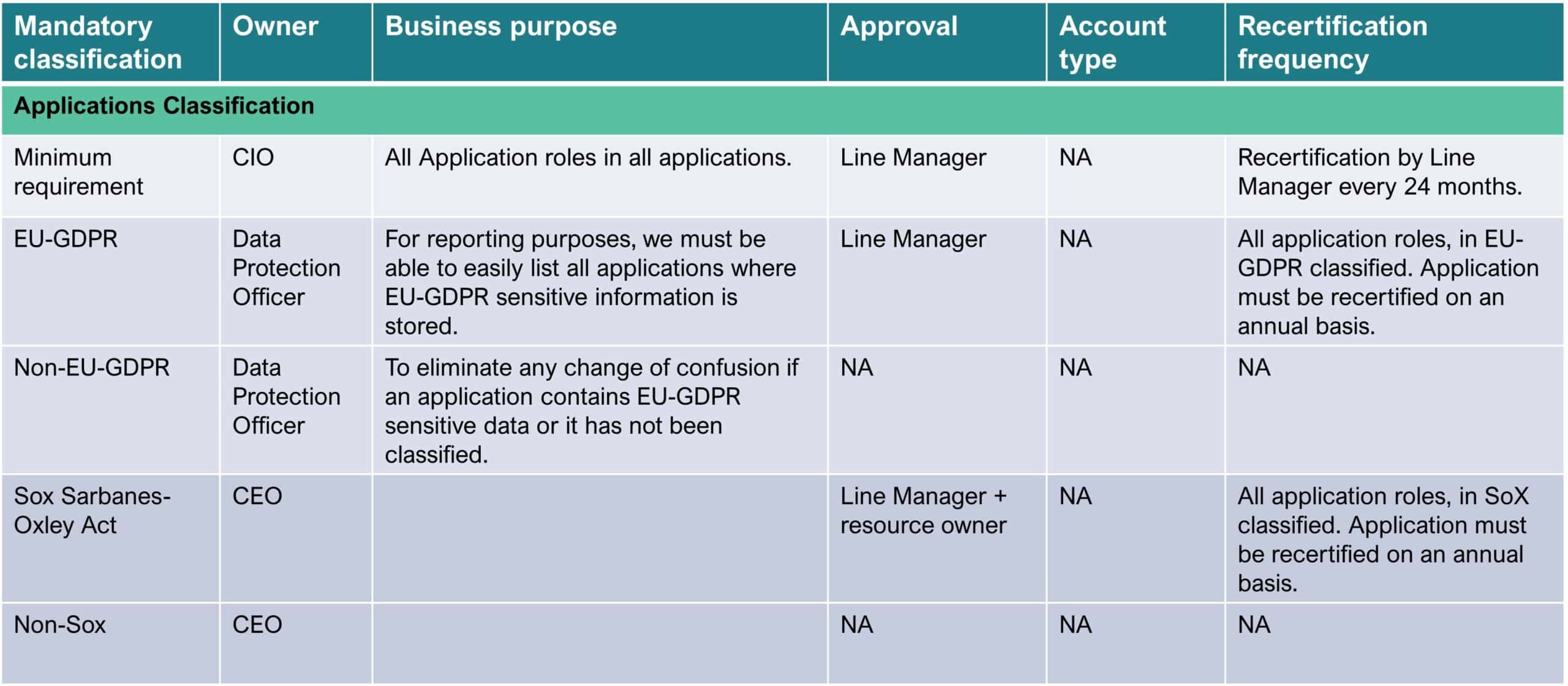 Figure 1: Application schema example
Figure 1: Application schema example
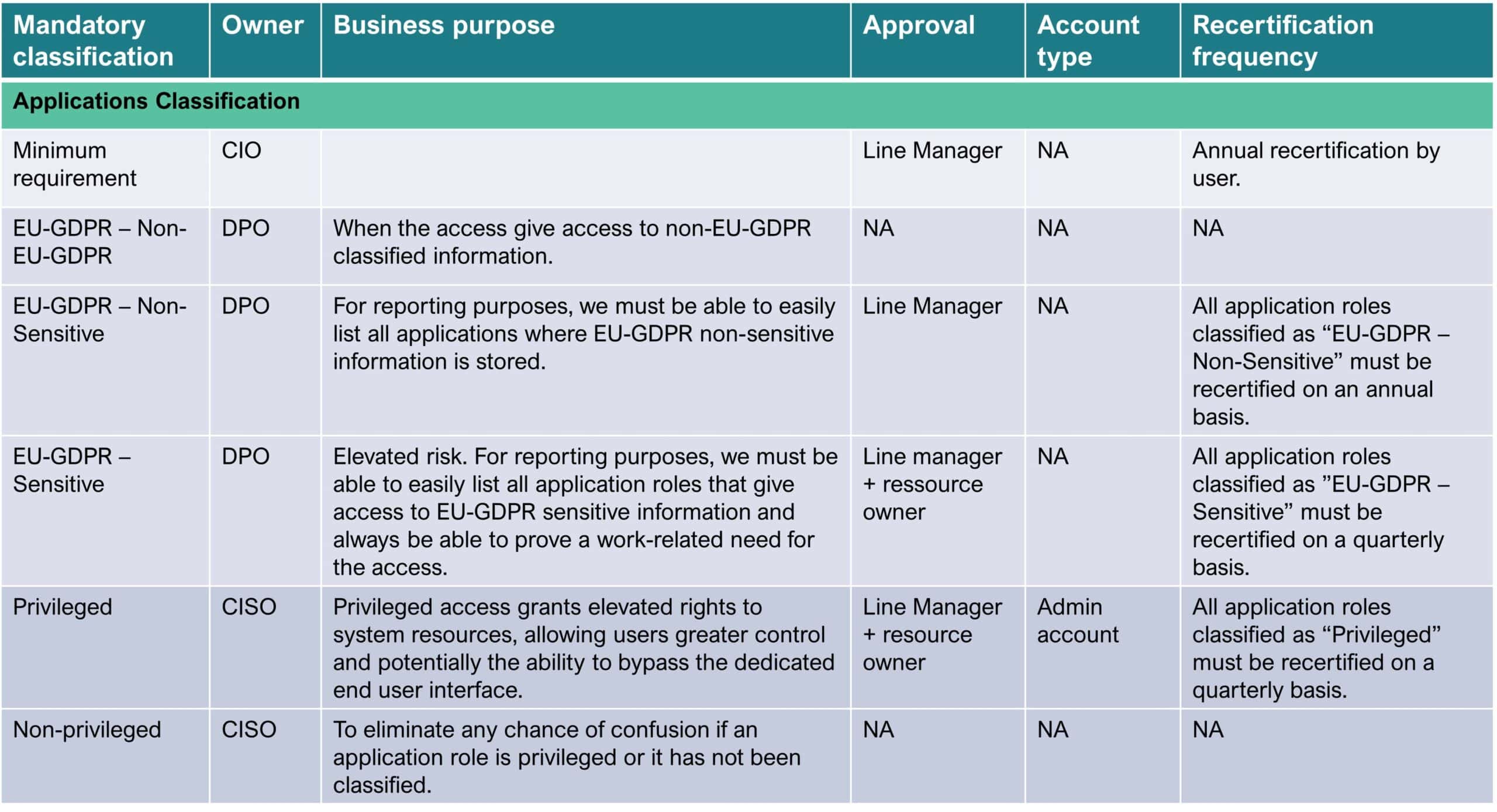 Figure 2: Roles classification schema example
Figure 2: Roles classification schema example
Conclusion
As we have seen, information classification for business and the classification process for IGA are very different. Information classification for business supports the business process but does not satisfy industry-specific requirements for security and data protection. IGA classification schema is an essential design element required to stay compliant with prominent cybersecurity frameworks. For a schema to be effective, each classification category must provide a valid business use case for creating it. Classification categories require an identity lifecycle management setup to ensure the ongoing integrity and quality of the schema.
For a more comprehensive look at creating a classification schema for your IGA system, watch this webinar.






